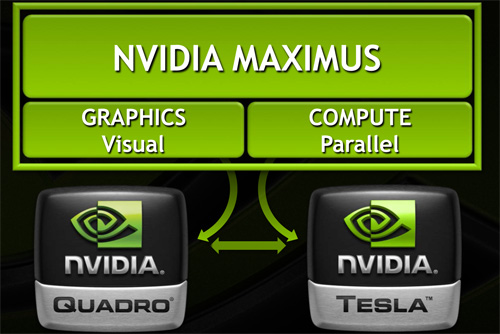
Back at SIGGRAPH 2011 NVIDIA announced Project Maximus, an interesting technology initiative to allow customers to combine Tesla and Quadro products together in a single workstation and to use their respective strengths. At the time NVIDIA didn’t have a launch date to announce, but as this is a software technology rather than a hardware product, the assumption has always been that it would be a quick turnaround. And a quick turnaround it has been: just over 3 months later NVIDIA is officially launching Project Maximus as NVIDIA Maximus Technology.

With Maximus NVIDIA is seeking to do a few different things, all of which come back to a single concept: utilizing Quadro and Tesla cards together at the tasks they’re best suited at. This means using Quadro cards for graphical tasks while using Tesla for compute tasks where direct graphical rendering isn’t necessary. Ultimately this seems like an odd concept at first – high end Quadros are fully compute capable too – but it’s something that makes more sense once we look at the current technical limitations of NVIDIA’s hardware, and what use cases they’re proposing.
Combining Quadro & Tesla: The Technical Details
The fundamental base of Maximus is NVIDIA’s drivers. For Maximus NVIDIA needed to bring Quadro and Tesla together under a single driver, as they previously used separate drivers. NVIDIA has used a shared code base for many years now, so Tesla and Quadro (and GeForce) were both forks of the same drivers, but those forks needed to be brought together. This is harder than it sounds as while Quadro drivers are rather straightforward – graphical rendering without all the performance shortcuts and with support for more esoteric features like external synchronization sources – Tesla has a number of unique optimizations, primarily the Tesla Compute Cluster driver, which moved Tesla out from under Windows’ control as a graphical device.
The issue with the forks had to be resolved, and the result was that NVIDIA was finally able to merge the codebase back into a single Quadro/Tesla driver as of July with the 275.xx driver series.
This brings us back to Optimus. With Optimus NVIDIA’s goal was to replace manual GPU muxing with a fully transparent system so that users never needed to take any extra steps to use a mobile GeForce GPU alongside Intel’s IGPs, or for that matter concern themselves with what GPU was being used. Optimus would – and did – take care of it all by sending lightweight workloads to the IGP while games and certain other significant workloads were sent to the NVIDIA GPU.
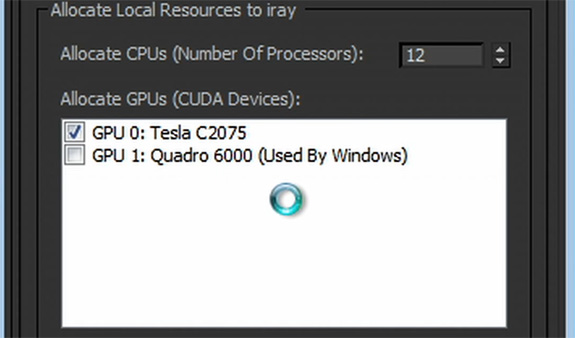
As with Optimus, NVIDIA’s desires here are rather straightforward: the harder something is to use, the slower the adoption. Optimus made it easier to get NVIDIA GPUs in laptops, and Maximus will make it easier to get CUDA adopted by more programs. Requiring developers to do any extra work to use CUDA is just one more thing that can go wrong and keep CUDA from being implemented, which in turn removes a reason for hardware buyers to purchase a high-end NVIDIA product.
Why Combine Quadro & Tesla?
So far we’ve covered how NVIDIA will be combining Quadro, but the more interesting question is “why?” In the NVIDIA hierarchy, Quadro is NVIDIA’s leading product. On the graphics side it’s fully unlocked, supporting quad-buffers, uncapped geometry performance, and uncapped viewport performance, while on the compute side it offers full speed FP64 support. Furthermore it’s available in the same configurations as a Tesla card, featuring the same number of CUDA cores and memory. Short of TCC, if you can compute it on a Tesla, you can compute it on a Quadro.
This actually creates some complexities for both NVIDIA and users. On a technical level, Fermi’s context switching is relatively fast for a GPU, but on an absolute level it’s still slow. CPUs can context switch in a fraction of the time, giving the impression of a concurrent thread execution even when we know that’s not the case. Furthermore for some reason context switching between rendering and compute on Fermi is particularly expensive, which means the number of context switches needs to be minimized in order to keep from wasting too much time just on context switching.
As a result of the time needed to context switch, Quadro products are not well suited to doing rendering and compute at the same time. They certainly can, but depending on what applications are being used and what they’re trying to do the result can be that compute eats up a great deal of GPU time, leaving the GUI to only update at a few frames per second with significant lag. On the consumer side NVIDIA’s ray-tracing Design Garage tech demo is a great example of this problem, and we took a quick video on a GTX 580 showcasing how running the CUDA based ray-tracer severely impacts GUI performance.
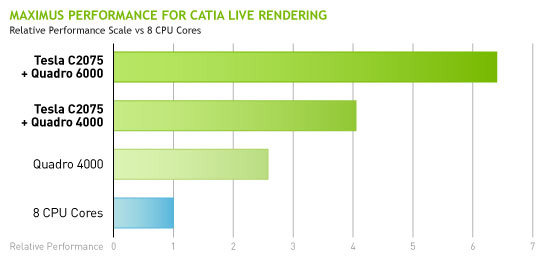
It’s worth noting that this situation closely mirrors the situation for software developers. For debug purposes NVIDIA recommends programmers have two GPUs, so that one GPU can be locked down debugging a compute or rendering task as necessary, while the other GPU is available to display the results. So NVIDIA encouraging users to have two GPUs for technical reasons is not new, but it is expanded. It also means there’s an obvious avenue for further development as NVIDIA wants to move GPU multitasking closer and closer to where CPU multitasking is today.
Moving on, the second reason NVIDIA is pursing Maximus is a result of their own actions. Because Quadro is NVIDIA’s leading product, it commands a leading price: a Quadro 6000 card is $3500 or more. This is a product of NVIDIA’s well engineered market segmentation – a GF110 GPU can be in a $500 GTX 580, a $2500 Tesla C2075, or a $3500 Quadro 6000. By disabling a few critical features on other products (e.g. geometry performance or FP64 performance) NVIDIA can push customers into buying a product at a price NVIDIA believes is best for the target market.
So what’s the problem? The Quadro 6000 is both a highly capable rendering product at a highly capable compute product, but not every professional user needs that much rendering power even if they need the compute power. Those users still need a Quadro card for its uncapped rendering performance, but they don’t necessarily need features such as Quadro 6000’s massive geometry throughput. The result is that NVIDIA was pricing themselves right out of their own market.
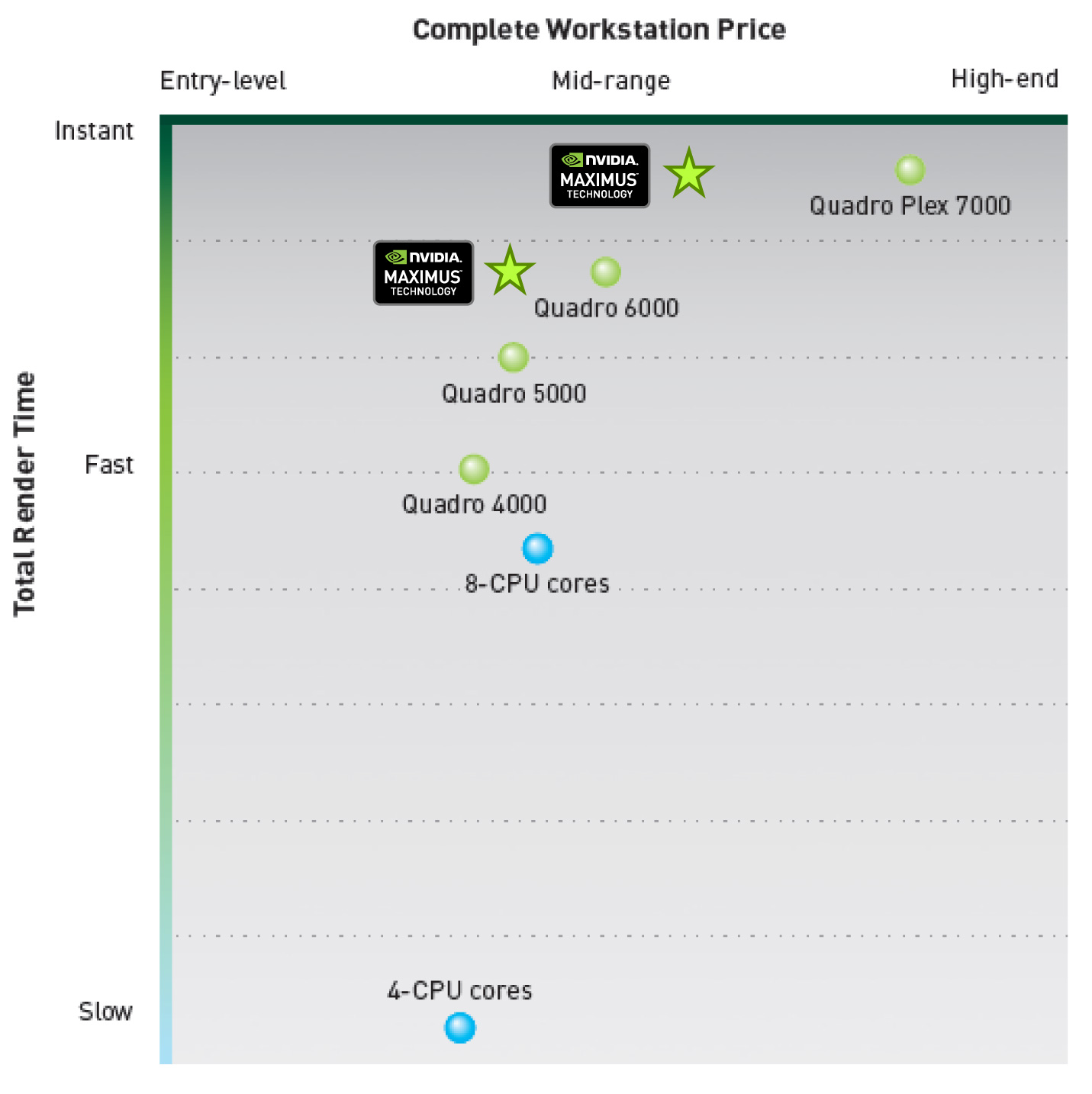
Final Words
Wrapping things up, NVIDIA has made it clear that they’re going to be pushing Maximus hard right out of the gate. Today of course was also the launch of Intel’s new Sandy Bridge E platform for high-end desktops and workstations, and in this industry there’s very little coincidence. It’s in NVIDIA’s interest to latch into workstation upgrade sales, and this is how you do it. They’ve already lined up HP, Lenovo, Fujitsu, and Dell to offer workstations pre-configured for Maximus, and we’re told those workstations will be made available for purchase today.
As to whether Maximus will be successful or not, this is going to depend both on software and marketing. On the software side NVIDIA needs to deliver on the transparency Maximus promises to developers and users – the concept is simple, but for the professional market the execution must be precise. Optimus graphics switching misbehaves now and then, but professional users will not be as willing to put up with any undesired behavior out of Maximus.
Marketing on the other hand is equally about promoting Maximus and promoting CUDA. A lot of NVIDIA’s promotional material for Maximus could easily be confused for CUDA promotional material, and this is because the videos and case studies are largely about how CUDA improved a process or a product while Maximus was the icing on the cake. Though we consider CUDA old, the fact of the matter is that much of the professional market NVIDIA is targeting has still not heard of CUDA, or has a limited understanding at best. As such NVIDIA will be using the launch of Maximus to promote the benefits of CUDA to certain targeted markets such as manufacturing, design, and broadcasting, just as much as they will be promoting the benefits of having multiple GPUs.
Source: AnandTech
No comments:
Post a Comment